En esta entrada publico que ya subí el vídeo en youtube.com mi proyecto final, el cual realiza un análisis del módulo de circulación del sistema CÓDICE, haciendo uso de las herramientas vistas en la materia "Sistemas de soporte a la toma de decisiones".
Espero les sea de utilidad.
Saludos.
17 diciembre 2010
15 diciembre 2010
Visualización de datos
Esta entrada esta dedicada a la visualización de datos.
La visualización es una herramienta importante para la toma de desciciones ya que nos permite comprender la información de una forma clara y más rapida, ver tendencias, factores anomalias o posibles problemas. Actualmente existen diversas herramientas para la visualisación de información, unas más potentes y flexibles que otras.
Para demostrar el uso de estas herramientas utilice el progama R para mostrar la información correspondiente a los prestamos realizados durante el año 2009 para cada una de las bibliotecas de la UANL que utilizan el sistema automatizado para realizar los prestamos. También utilice la información de la cantidad de material que contiene cada biblioteca.
La visualización es una herramienta importante para la toma de desciciones ya que nos permite comprender la información de una forma clara y más rapida, ver tendencias, factores anomalias o posibles problemas. Actualmente existen diversas herramientas para la visualisación de información, unas más potentes y flexibles que otras.
Para demostrar el uso de estas herramientas utilice el progama R para mostrar la información correspondiente a los prestamos realizados durante el año 2009 para cada una de las bibliotecas de la UANL que utilizan el sistema automatizado para realizar los prestamos. También utilice la información de la cantidad de material que contiene cada biblioteca.
En la siguiente gráfica podemos observar una gráfica de burbujas, en donde el tamaño de la burbuja representa la cantidad de material de la biblioteca en relación a las demas bibliotecas, cuanto más grande la burbuja más grande la cantidad de materiales que contiene. La altura de la burbuja (o sea el eje y) representa la cantidad de prestamos realizados en el año2009 por la biblioteca, este valor también se encuentra en el centro de la burbuja. El nombre de las bibliotecas los omití intencionalmente.

De la gráfica anterior podemos observar que las bibliotecas con mayor cantidad de materiales no son las que tienen mayor tráfico de prestamo de material, siendo una de las bibliotecas pequeñas la que tiene el mayor trafico de prestamos.
Les dejo la liga del articulo del cual tomé la información para realizar la gráfica
14 diciembre 2010
Algoritmos en línea
Los algoritmos en línea son aquellos en los cuales la información se va ingresando parte por parte, por lo que no se conoce toda la información y se debe de decir en el momento en el que llega la información lo que se va a hacer sin conocer las entradas futuras. Estos algoritmos a diferencia de los algoritmos fuera de línea, que si conocen toda la información del sistema desde un inicio, no garantizan que se encuentre una solución óptima. El estudio de estos algoritmos se centra en la calidad de la decisión tomada al momento de que llega información nueva.
Aplicación en sistemas de alarmas contra desastres naturales
La aplicación de algoritmos en línea para redes de señales de alarmas de desastres naturales podría ser la de buscar los caminos más rápidos a los nodos que todavía no se les ha informado la noticia considerando que algunos de los nodos pueden sufrir desperfectos o estar deshabilitados. Cuando se vaya visitando los nodos para informar la advertencia se podría analizar los nodos vecinos y tomar una decisión sobre cuál es la mejor opción y diseminar el mensaje más rápido.
Los algoritmos en línea considerados para resolver problemas de redes usan la idea de asociar con cada vínculo un costo que es exponencial a la fracción de la capacidad del vínculo asignado a los circuitos salientes. El costo asociado con un vínculo en la red puede ser visto como el valor a la variable dual asociada con el vínculo mismo. El algoritmo entonces enruta cada solicitud a un costo mínimo.
Aplicación en sistemas de alarmas contra desastres naturales
La aplicación de algoritmos en línea para redes de señales de alarmas de desastres naturales podría ser la de buscar los caminos más rápidos a los nodos que todavía no se les ha informado la noticia considerando que algunos de los nodos pueden sufrir desperfectos o estar deshabilitados. Cuando se vaya visitando los nodos para informar la advertencia se podría analizar los nodos vecinos y tomar una decisión sobre cuál es la mejor opción y diseminar el mensaje más rápido.
Los algoritmos en línea considerados para resolver problemas de redes usan la idea de asociar con cada vínculo un costo que es exponencial a la fracción de la capacidad del vínculo asignado a los circuitos salientes. El costo asociado con un vínculo en la red puede ser visto como el valor a la variable dual asociada con el vínculo mismo. El algoritmo entonces enruta cada solicitud a un costo mínimo.
Algoritmos genéticos
Los algoritmos genéticos fueron creados asimilando el comportamiento de la evolución de los seres vivos la cual plantea que los seres con mejores cualidades o mejor adaptados son los que tienen mayor oportunidad de sobrevivir, y por lo tanto, de generar una mayor y mejor preparada descendencia. Los algoritmos genéticos caben dentro de la rama de la inteligencia artificial.
Los algoritmos genéticos están basados en probabilidad y pueden ayudarnos a encontrar soluciones en problemas que no tienen una función específica para su solución. Y su campo de uso es muy amplio.
El proceso que el algoritmo genético intenta imitar es el de la selección natural en el cual a partir de una muestra aleatoria de una población en donde los ejemplares, que son las posibles soluciones que se pueden dar al problema, con mejores características o mejor ponderados son los que tendrán mayor probabilidad de cruzarse. El resultado del cruce de estos individuos creará una generación con mejores características que sus ancestros, lo que en teoría deberá acercarnos cada vez más a una solución óptima. Este ciclo se repite cierta cantidad de veces hasta que se considere que se llega a una solución óptima. Algunos algoritmos evolutivos más complejos pueden irse mejorando conforme se vayan realizando las iteraciones para cada generación, lo que permite tener un algoritmo inteligente que va aprendiendo de acuerdo a su experiencia.
Es importante hacer notar que debemos de tener una función que nos deberá ponderar de manera efectiva cuales son los ejemplares con mejores cualidades, para que tengan una mejor oportunidad de crear nuevas generaciones. Estas funciones deberán de “castigar” las peores soluciones y “premiar” las mejores.
El algoritmo genético simple tiene la siguiente estructura:
BEGIN
Generar una población inicial
Computar la función de evaluación de cada individuo
WHILE NOT Terminado DO
BEGIN–producir una nueva generación
FOR Tamaño población
BEGIN --ciclo reproductivo
Seleccionar dos individuos de la generación anterior para el cruce
(probabilidad de selección proporcional a la función de evaluación del
individuo
Cruzar con cierta probabilidad los dos individuos obteniendo dos
descendientes
Mutar los dos descendientes con cierta probabilidad
Computar la función de los dos descendientes mutados
Insertar los dos descendientes mutados en la nueva población
END
IF la población ha convergido THEN
Terminado = True
END IF
END
END
La aplicación de los algoritmos evolutivos tienen las siguientes aplicaciones:
- Diseño automatizado de equipo industrial
- Diseño de sistemas de distribución de agua
- Aprendizaje de comportamiento de robots
- Optimización de estructuras moleculares
- Predicción
- Diseño de topología de redes computacionales
- Problema del viajante
- Etc.
Sistemas Expertos
Los sistemas expertos son llamados así porque emulan el comportamiento de un experto en un dominio concreto y en ocasiones son usados por éstos. Con los sistemas expertos se busca una mejor calidad y rapidez en las respuestas dando así lugar a una mejora de la productividad del experto.
Para nuestro interés un sistema experto es un conjunto de programas que, sobre una base de conocimientos, posee información de uno o más expertos en un área específica.
Puede entenderse como una rama de la inteligencia artificial, donde el poder de resolución de un problema en un programa de computadora viene del conocimiento de un dominio específico.
Estos sistemas imitan las actividades de un humano para resolver problemas de distinta índole (no necesariamente tiene que ser de inteligencia artificial). También se dice que un sistema experto se basa en el conocimiento declarativo (hechos sobre objetos, situaciones) y el conocimiento de control (información sobre el seguimiento de una acción).
Para que un sistema experto sea herramienta efectiva, los usuarios deben interactuar de una forma fácil, reuniendo dos capacidades para poder cumplirlo:
Explicar sus razonamientos o base del conocimiento: los sistemas expertos se deben realizar siguiendo ciertas reglas o pasos comprensibles de manera que se pueda generar la explicación para cada una de estas reglas, que a la vez se basan en hechos.
Adquisición de nuevos conocimientos: son mecanismos de razonamiento que sirven para modificar los conocimientos anteriores. Sobre la base de lo anterior se puede decir que los sistemas expertos son el producto de investigaciones en el campo de la inteligencia artificial ya que ésta no intenta sustituir a los expertos humanos, sino que se desea ayudarlos a realizar con más rapidez y eficacia todas las tareas que realiza.
Las tareas que realiza un sistema experto son:
Monitorización: La monitorización es un caso particular de la interpretación, y consiste en la comparación continua de los valores de las señales o datos de entrada y unos valores que actúan como criterios de normalidad o estándares
Diseño: Diseño es el proceso de especificar una descripción de un artefacto que satisface varias características desde un número de fuentes de conocimiento.
Planificación: La planificación es la realización de planes o secuencias de acciones y es un caso particular de la simulación. Está compuesto por un simulador y un sistema de control. El efecto final es la ordenación de un conjunto de acciones con el fin de conseguir un objetivo global.
Control: Un sistema de control participa en la realización de las tareas de interpretación, diagnóstico y reparación de forma secuencial. Con ello se consigue conducir o guiar un proceso o sistema.
Simulación: El empleo de los SE para la simulación viene motivado por la principal característica de los SE, que es su capacidad para la simulación del comportamiento de un experto humano, que es un proceso complejo.
Instrucción: Un sistema de instrucción realizara un seguimiento del proceso de aprendizaje. El sistema detecta errores ya sea de una persona con conocimientos e identifica el remedio adecuado, es decir, desarrolla un plan de enseñanza que facilita el proceso de aprendizaje y la corrección de errores.
Recuperación de información: Lo que diferencia a estos sistemas de un sistema tradicional de recuperación de información es que éstos últimos sólo son capaces de recuperar lo que existe explícitamente, mientras que un Sistema Experto debe ser capaz de generar información no explícita, razonando con los elementos que se le dan.
Una aplicación que puede utilizarse para el sistema de bibliotecas, específicamente en lo concerniente a los prestamos de materiales puede ser el pronosticar los días para poner a disposición del público los materiales que se encuentran en reserva, por ejemplo cuando hay mucha demanda de material y no tener que esperarse que los usuarios tengan que solicitar el material al encargado. Esto podría ayudar a prepararse con tiempo para estas situaciones al personal y el material con anticipación.
De la base de datos de préstamos del 2009 en la UANL generamos una gráfica junto con los intervalos donde se detecto que se necesitan sacar los materiales de reserva (3 intervalos encontrados), ya que los prestamos rebasan los 1900 prestamos diarios de acuerdo a la predicción obtenida mediante las dobles medias móviles con un intervalo de 3 valores hacia atrás.

De color azul podemos ver los prestamos reales y de color verde los intervalos donde se sugiere sacar los materiales de reserva.
Herramientas de minería de datos
En esta actividad revisaré la herramienta de código abierto KNIME para la minería de datos.
Esta herramienta permite trabajar mediante un modelo de flujo de trabajo, el cual, documenta y guarda el proceso de análisis en el orden en el que fue concebido e implementado, asegurando que los resultados intermedios estén siempre disponibles.
Las funcionalidades con las que cuenta Knime son:
Lectura y escritura de archivos y bases de datos
Manipulación de datos: pre procesamiento de los datos ingresados con filtros, agrupamiento, pivoteo, normalización, agregación, particionamiento, etc.
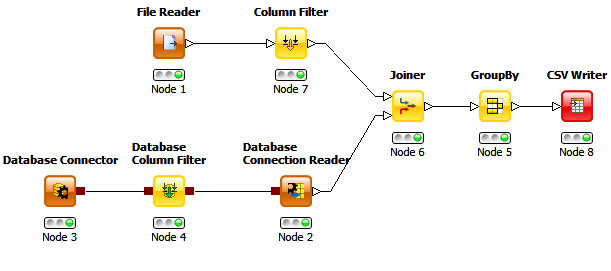
Vistas: Visualización de datos y resultados a través de varias vistas interactivas, permitiendo exploración de datos interactiva.

Minería: utiliza los datos del estado de la técnica como algoritmos de minería de la agrupación, inducción de reglas, árboles de decisión, reglas de asociación, Bayes ingenuo, redes neuronales, máquinas de vectores soporte, etc., para comprender mejor sus datos

Unas de las ventajas de Knime es que no es necesario instalar el paquete en la computadora, puede correr desde la carpteta donde se tengan los archivos de la aplicación. Lo que si puede ocasionar problemas es el manejo de la memoria, ya que para procesos complicados se necesita tener una buena capacidad en memoria RAM si no queremos que se inhiba la computadora.
A continuación dejo unos videos de cómo se utiliza la herramienta
Manipulación de imágenes
Esta entrada esta enfocada a la manipulación de imágenes. En mi caso me toco manipular las imágenes de manera que se pueda cambiar al color de una region en particular del mismo color.




Para realizar esto utilice la herramienta octave con el modulo image para la manipulación de imágenes.
Primero genere una matriz de 10 x 10 de ceros y unos de manera aleatoria mediante la siguiente instrucción:

Para representar esta matriz como una imagen utilice la siguiente instrucción
imgplot(y)
imgplot(y)
La cual genero la siguiente imagen:

Para realizar el cambio de color de una región seleccionada de la imagen, realice una rutina la cual esta compuesta por funciones
La primera es la función principal, la cual ejecuta las demás y devuelve la matriz ya modificada. La idea general de esta rutina es la de ir revisando los valores adyacentes al pixel indicado para revisar si es del mismo color que el principal, si es así le cambia el color y revisa los valores adyacentes a ese valor que se le acaba de cambiar el color. Esto lo realiza mediante funciones recursivas. A continuación dejo las funciones que genere:
function res = colorear(m,x,y)
#Funcion que cambia de color los pixeles adyacentes al indicado
#m es la matriz a la cual se le quiere manipular
#x es la fila del valor seleccionado para cambiar los valores adyacentes del mismo color
#y es la fila del valor seleccionado para cambiar los valores adyacentes del mismo color
z = m(x,y);
m = colorearsec(m,x,y,z);
res = m;
endfunction
function res = colorearsec(m,x,y,z)
#Función recursiva que cambia de color el pixel indicado y ejecuta las funciones para cambiar los adyacentes
m(x,y) = 3;
m = derecha(m,x,y,z);
m = abajo(m,x,y,z);
m = izquierda(m,x,y,z);
m = arriba(m,x,y,z);
res = m;
endfunction
function res = derecha(m,x,y,z)
#Función que cambia de color el pixel a la derecha del especificado
[x1,y1]= size(m);
if((y+1)
if(m(x,y+1)==z)
m(x,y+1)=3;
m = colorearsec(m,x,y+1,z);
endif
endif
res = m;
endfunction
function res = izquierda(m,x,y,z)
#Función que cambia de color el pixel a la izquierda del especificado
[x1,y1]= size(m);
if((y-1)>0)
if(m(x,y-1)==z)
m(x,y-1)=3;
m = colorearsec(m,x,y-1,z);
endif
endif
res = m;
endfunction
function res = abajo(m,x,y,z)
#Función que cambia de color el pixel a abajo del especificado
[x1,y1]= size(m);
if((x+1)
if(m(x+1,y)==z)
m(x+1,y)=3;
m = colorearsec(m,x+1,y,z);
endif
endif
res = m;
endfunction
function res = arriba(m,x,y,z)
#Función que cambia de color el pixel arriba del especificado
[x1,y1]= size(m);
if((x-1)>0)
if(m(x-1,y)==z)
m(x-1,y)=3;
m = colorearsec(m,x-1,y,z);
endif
endif
res = m;
endfunction
Al ejecutar la rutina para cambiar el color de los pixeles adyacentes al que se encuentra en la posición y(1,2) tenemos el siguiente resultado:

Como podemos observar los valores adyacentes al pixel seleccionado cambiaron al valor '3'.
Si graficamos esta matriz tenemos el siguiente resultado:

El problema que encontré con estas funciones es que como utiliza funciones recursivas es fácil que se llegue al limite de recursividad de la herramienta octave por lo que tendremos que aumentar este limite. Aun habiendo hecho esto la herramienta tiende a fallar cuando son muchas llamadas recursivas. Trate de solucionar este detalle creando rutinas que utilicen ciclos pero el proceso es muy lento. Como quiera dejo las rutinas creadas por si quieren darle un vistazo.
function res = colorear2(m,x,y)
z = m(x,y);
m(x,y) = 3;
[x1,y1] = size(m);
encontrado = 0;
do
encontrado = 0;
for i = 1:x1
for j = 1:y1
if (m(i,j)==z)
if ((derecha2(m,i,j,z) ==1)|(izquierda2(m,i,j,z)==1)|(arriba2(m,i,j,z)==1)|(abajo2(m,i,j,z)==1))
encontrado = 1;
m(i,j) = 3;
break;
endif
endif
endfor
if (encontrado == 1)
break;
endif
endfor
until encontrado == 0
res = m;
endfunction
function res = derecha2(m,x,y,z)
#Función que cambia de color el pixel a la derecha del especificado
[x1,y1]= size(m);
res = 0;
if(m(x,y)==z)
if((y+1)
if(m(x,y+1)==3)
res = 1;
endif
endif
endif
endfunction
function res = izquierda2(m,x,y,z)
#Función que cambia de color el pixel a la izquierda del especificado
[x1,y1]= size(m);
res = 0;
if(m(x,y)==z)
if((y-1)>0)
if(m(x,y-1)==3)
res = 1;
endif
endif
endif
endfunction
function res = abajo2(m,x,y,z)
#Función que cambia de color el pixel a abajo del especificado
[x1,y1]= size(m);
res = 0;
if(m(x,y)==z)
if((x+1)
if(m(x+1,y)==3)
res = 1;
endif
endif
endif
endfunction
function res = arriba2(m,x,y,z)
#Función que cambia de color el pixel arriba del especificado
[x1,y1]= size(m);
res = 0;
if(m(x,y)==z)
if((x-1)>0)
if(m(x-1,y)==3)
res = 1;
endif
endif
endif
endfunction
Datos anomalos
Esta entrada esta dedicada al estudio de anomalías en los conjuntos de datos
Un dato anómalo es aquel que se encuentra a una distancia anormal de los demás datos de una muestra aleatoria de datos. En este sentido la definición deja en manos del analista el decidir lo que considera anormal, para esto es necesario identificar los datos que se consideran normal.
Para el siguiente ejercicio utilice la base de datos de prestamos del sistema de bibliotecas de la UANL en el 2009.
Utilice para realizar los cálculos y las gráficas la herramienta Octave con el modulo outliers.
Para cargar los valores en una variable dentro de Octave utilice la siguiente instrucción:
x = csvread("/home/carlos/Documentos/Prestamos2009")
En la cual se almacena la matriz de los prestamos realizados en el 2009 en una columna y en otra el día en que se realizo el préstamo. Para nuestro estudio no nos interesa el día exacto en el que se realizo el préstamo, solo la cantidad de prestamos por día, por lo que solo utilizaremos la columna con los valores del préstamo.
Para graficar los prestamos realizados utilice la siguiente instrucción:
plot(x(:,2),'b*')
En la cual le indico a la herramienta que deseo graficar los valores de la segunda columna, que los ponga de color azul y que utilice el símbolo '*' para representar los valores en la gráfica
La gráfica de dispersión de los prestamos realizados en la UANL tienen el siguiente aspecto:

Para obtener el valor que se encuentra mas alejado del comportamiento normal de los demás, utilice la siguiente instrucción:
[out2] = outlier(x(:,2),0,0)
El cual arrojo el valor: 2405
con esta instrucción ya tengo cual es el valor mas alejado del comportamiento normal dentro del conjunto de datos, pero todavía no se en que posición se encuentra dentro del vector. Para solucionar esto utilizo la siguiente instrucción:
[out] = outlier(x(:,2),0,1)
La cual almacena en la variable “out” un vector con valores 0 y 1, en donde 0 significa que el dato almacenado en esa posición del vector inicial tienen comportamiento normal, a contraposición de los que tienen valor 1 (que en este caso solo envía un solo valor)
Para poder observar en la gráfica el punto que se considera anómalo, multiplico el vector resultante con el valor anómalo y lo guardo en un segundo vector con la siguiente instrucción:
out3 = out*out2
Ahora puedo graficar los dos vectores y observar cual es el dato anómalo dentro de la gráfica de dispersión utilizando la función Plot:
plot(x(:,2),'b*',out3,'r*')
La gráfica resultante muestra los valores dentro del conjunto de datos de color azul y el dato anómalo lo muestra de color rojo como se ve a continuación

{kind=link}
12 diciembre 2010
Pronósticos de series
El objetivo de esta entrada es el investigar la generación de pronósticos a partir de una serie. La herramienta que utilice para generar estos pronósticos fue Dobles Medias móviles las cuales son más acertadas cuando el comportamiento de la variable que estudiamos tiene una tendencia variable. Esta herramienta utiliza como predicción del periódo T+1 el valor del periódo T más la media de los incrementos observados en la muestra (1,2,…T)
Esta técnica supone dos medias móviles. La primera sobre el valor original de la variable y la segunda sobre la media móvil simple. La primera calcula el periodo T y con la segunda obtenemos su incremento. La predicción para más allá de un periódo supone una perdida de información o el uso de predicciones.
Para obtener la media móvil la obtenemos de la siguiente formula:

Para obtener la segunda media móvil utilizamos la siguiente fórmula:

Para obtener la predicción la obtenemos de la siguiente fórmula:

Donde

Para obtener los errores de las predicciones se utilizaron las siguientes fórmulas:

A continuación muestro los resultados de las predicciones que obtuve con la los prestamos de libros registrados en el 2009 en la UANL. He eliminado los prestamos realizados los sábados ya que son muy pocos (máximo 250) en comparación con los que se realizan de lunes a viernes.
Para la generación de predicciones con medias móviles es necesario especificar la cantidad de valores anteriores que se tomarán en cuenta.
En la gráficas siguientes podremos observar de color azul los prestamos registrados en el sistema y de color rojo los valores generados mediante las dobles medias móviles.
En primer instancia realicé la prueba con 30 valores anteriores para generar las predicciones y obtuve los siguientes resultados:

Se puede observar que la predicción tiende a tener un comportamiento parecido a los valores reales pero con muy poca precisión.
Estos son los resultados de error que de esta prueba:
Error absoluto de la media (MAD) | 14.5257978 |
Error absoluto porcentual de la media (MAPE) | 0.28473171 |
Desviación porcentual absoluta de la media (PMAD) | 0.00753047 |
Error cuadrático de la media (MSE) | 386527.106 |
Raíz del error cuadrático de la media (RMSE) | 621.713041 |
Para la segunda prueba reduje el número de valores a considerar para la predicción a 15 y obtuve los siguientes resultados:

Se puede observar que los valores pronosticados tienden a ser más precisos que la prueba anterior. En los valores de los errores se puede observar que el error absoluto de la media se incrementa pero los valores del error cuadrático de la media y la raíz del error cuadrático disminuyen.
Error absoluto de la media (MAD) | 71.6742415 |
Error absoluto porcentual de la media (MAPE) | 0.18077682 |
Desviación porcentual absoluta de la media (PMAD) | 0.03715738 |
Error cuadrático de la media (MSE) | 248015.863 |
Raíz del error cuadrático de la media (RMSE) | 498.01191 |
Continué disminuyendo la cantidad de valores a considerar para generar la predicción a 10 y obtuve los siguientes resultados:

Se puede observar que los valores son todavía más cercanos a los valores reales que en la prueba anterior.
También el error cuadrático de la media disminuye:
Error absoluto de la media (MAD) | 90.3441498 |
Error absoluto porcentual de la media (MAPE) | 0.16649666 |
Desviación porcentual absoluta de la media (PMAD) | 0.04683624 |
Error cuadrático de la media (MSE) | 169679.553 |
Raíz del error cuadrático de la media (RMSE) | 411.92178 |
Al generar las predicciones con 5 valores anteriores se obtuvo la siguiente gráfica:

A simple vista podría decirse que se ajusta muy bien a los valores reales pero al obtener los valores de los errores de la predicción se puede observar que son mayores que la prueba anterior, por lo que puede concluirse que la cantidad optima de valores a tomar para generar la predicción con este método para este caso está entre 5 y 10 valores.
Error absoluto de la media (MAD) | 242.963291 |
Error absoluto porcentual de la media (MAPE) | 0.30465659 |
Desviación porcentual absoluta de la media (PMAD) | 0.16433797 |
Error cuadrático de la media (MSE) | 198008.115 |
Raíz del error cuadrático de la media (RMSE) | 444.981028 |
Suscribirse a:
Comentarios (Atom)